智能制造網的數據處理與存儲支持 驅動工業4.0的核心引擎
在工業4.0的浪潮中,智能制造網作為連接物理世界與數字世界的神經網絡,正深刻改變著傳統制造業的面貌。其高效、精準的運作,離不開強大而可靠的數據處理與存儲支持服務。這些服務不僅是信息流轉的基石,更是實現智能化決策、優化生產流程、提升核心競爭力的關鍵引擎。
一、智能制造網的數據洪流與挑戰
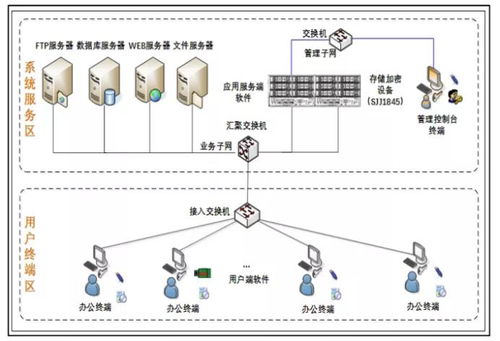
現代智能工廠中,數以億計的傳感器、控制器、機器人和智能設備持續不斷地產生海量數據,涵蓋設備狀態、生產過程、質量檢測、能耗物耗、供應鏈物流等方方面面。這些數據具有體量巨大(Volume)、類型多樣(Variety)、產生速度快(Velocity)和價值密度不均(Value)的典型“4V”特征。如何實時、準確、安全地采集、處理、分析并存儲這些數據,從中提煉出洞察與知識,是智能制造面臨的首要挑戰。數據處理與存儲支持服務,正是為解決這些挑戰而生。
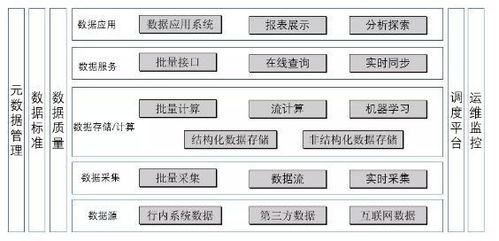
二、核心數據處理服務:從數據到洞察
1. 邊緣計算與預處理:在數據產生的源頭(如車間現場)就近進行初步處理,過濾噪聲、壓縮數據、執行實時分析并做出快速響應(如設備異常停機預警)。這顯著降低了網絡傳輸負載和云端處理壓力,滿足了極低延遲的控制需求。
2. 流式數據處理:對于生產線上高速產生的實時數據流(如視覺檢測圖像、振動傳感信號),流處理引擎能夠進行連續不斷的計算與分析,實現生產狀態的瞬時監控與動態調整。
3. 批量與交互式分析:對歷史數據進行深度挖掘與離線分析,用于工藝優化、預測性維護、質量根因分析等。提供交互式查詢工具,支持工程師和管理者靈活探索數據,快速獲得答案。
4. 人工智能與機器學習集成:數據處理平臺無縫集成AI/ML框架,利用歷史數據訓練模型,并將模型部署于邊緣或云端,實現缺陷自動分類、產能預測、參數優化等高級智能應用。
三、彈性可擴展的存儲支持體系
1. 分層存儲架構:根據數據的溫度(訪問頻率和重要性)采用不同的存儲介質和策略。熱數據(如實時監控數據)存入高性能閃存;溫數據(如近期生產日志)存入高速磁盤;冷數據(如歸檔的 historical 記錄)則可采用成本更低的磁帶或對象存儲。這實現了性能與成本的最佳平衡。
2. 多云與混合云存儲:為滿足數據主權、業務連續性、成本優化等需求,存儲服務支持將數據靈活分布在私有云、公有云及邊緣節點之間,實現統一管理和無縫流動。
3. 數據湖與數據倉庫:原始、多結構的海量數據可注入數據湖進行低成本存儲,保留其最大原始價值;經過清洗、轉換和建模的數據則可存入結構化的數據倉庫,支撐高效的企業級報表和商業智能分析。
4. 高可靠與安全性保障:通過多副本、糾刪碼、跨地域備份等技術確保數據持久不丟失。結合加密傳輸、靜態加密、細粒度訪問控制等手段,構建從網絡、應用到數據層的全方位安全防護體系,保護核心工藝數據和商業秘密。
四、服務價值與未來展望
強大的數據處理與存儲支持服務,賦能智能制造網實現:
- 生產透明化:全流程、全要素數據可視,消除信息孤島。
- 決策智能化:基于數據驅動的洞察,替代部分經驗決策,提升精準度。
- 運營敏捷化:快速響應市場變化與內部需求,實現柔性生產。
- 維護預測化:變被動維修為主動預測,大幅降低停機損失。
隨著5G、物聯網、數字孿生和AI技術的進一步融合,智能制造網的數據處理與存儲將向更實時、更智能、更自治的方向演進。邊緣智能將更加普及,云邊協同將更加緊密,數據作為核心生產要素的價值將被更深層次地挖掘和釋放,持續推動制造業向高質量、高效率、高柔性的新階段邁進。
如若轉載,請注明出處:http://www.quglzsl.cn/product/38.html
更新時間:2026-06-19 22:48:10